Article · Aug 18, 2023
Arbitrary Text : Data Source of Nested Repeating Group in Bubble
Arbitrary text: Use this to manually enter a static or dynamic string of text. The text entered can be further modified with any of our text type operators.
As per Bubble Manual,
-
Arbitrary text:
Use this to manually enter a static or dynamic string of text. The text entered will resolve to type Text and can be further modified with any of our text type operators.
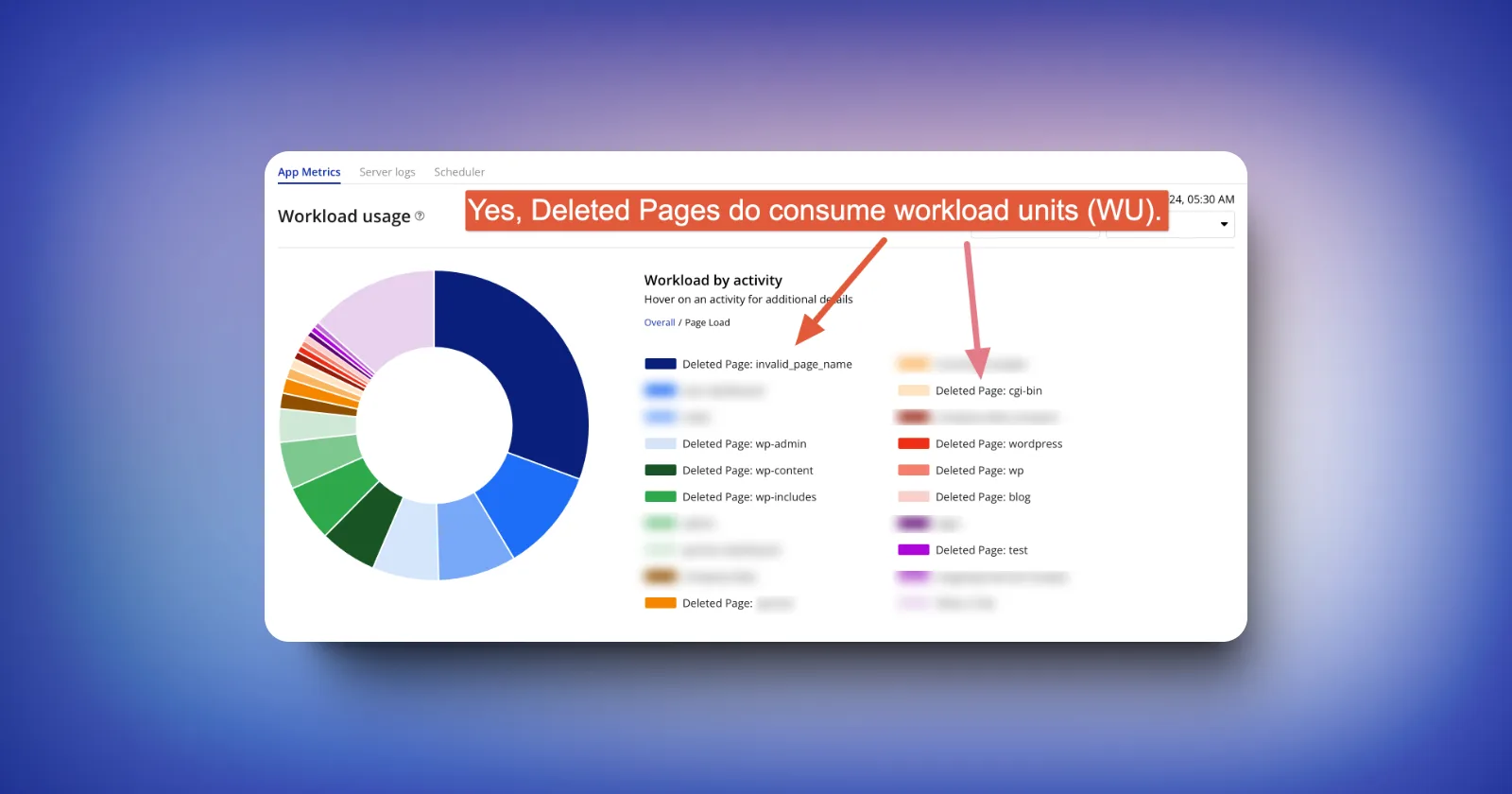
Since the inception of the New Pricing Model based on Workload Units, I am constantly looking for ways to optimise the Bubble applications I am building. I have realised that in many applications there are text-based data tables in which data stays the same or hardly changes once in 6-8 months and these data types are being used as data sources in repeating groups. For example data of Subscription Packages, Product Features etc.
Now as a bubble developer, one must know that fetching Data in the Repeating Group consumes WU(Workload Units) and as a developer you want to save as much WU as possible for your client/yourself. So here I am sharing what I am doing to save WU and Optimize my bubble application by not using a database as the Data source of the Repeating Group for static data.
As an example, Here I am using Arbitrary text with Splitby() as data source of Repeating Group in which I have to show different features of different products in Repeating Group.
Here is how I arranged text details of products in arbitrary text:
-
All the new products will start from a new line. As you can see in the image below, Product 1, Product 2 and Product 3 are starting from the new line.
-
All the products will have highlights and features
-
Highlights are separated via ’~’
-
Features are separated via ’,’
-
Products, Highlights and Features are also separated via ’~’
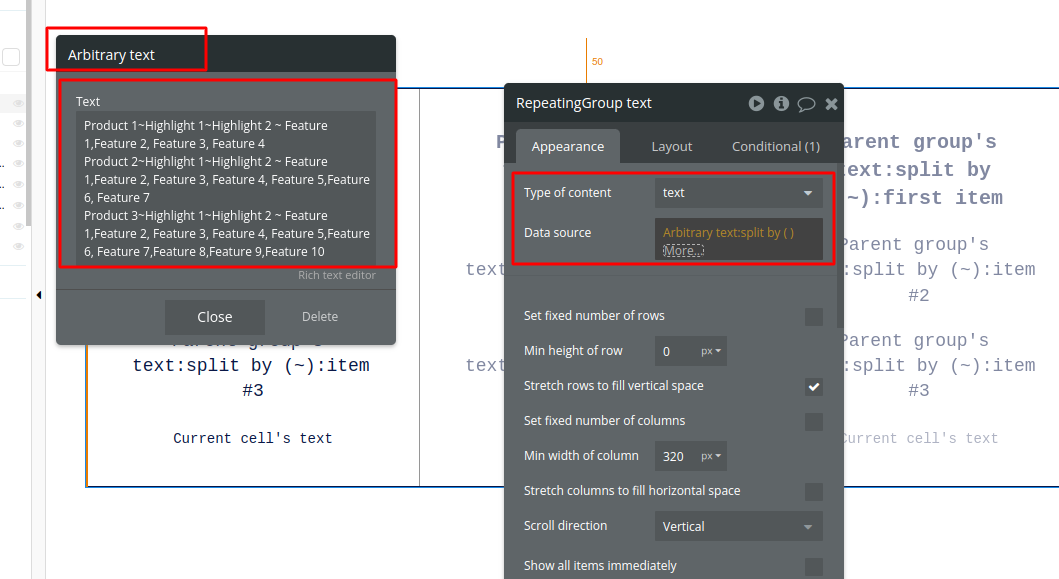
With this, each cell of the repeating group will have Product 1, Product 2 and Product 3 as data sources for that individual cell. If you add an ‘n’ number of products in this Arbitrary text, the n number of cells will be automatically filled with their own product data in the Repeating Group.
Now each cell’s data has 3 parts:
-
Product Name
-
Product Highlights
-
Product Features
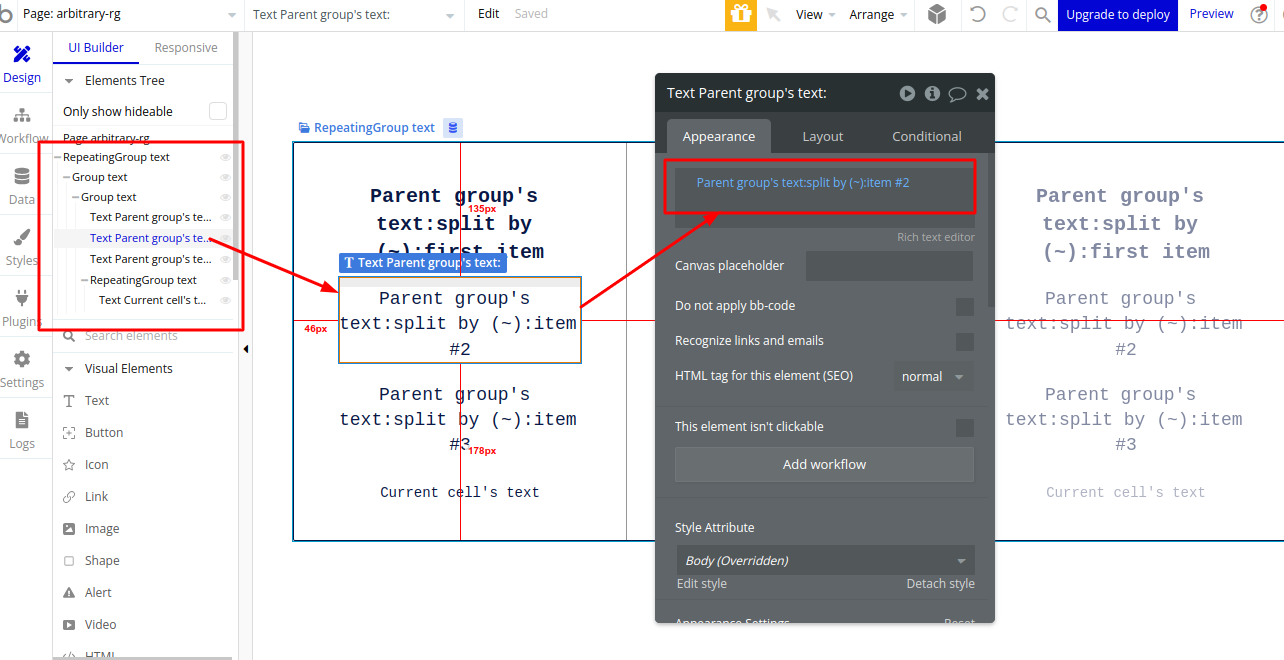
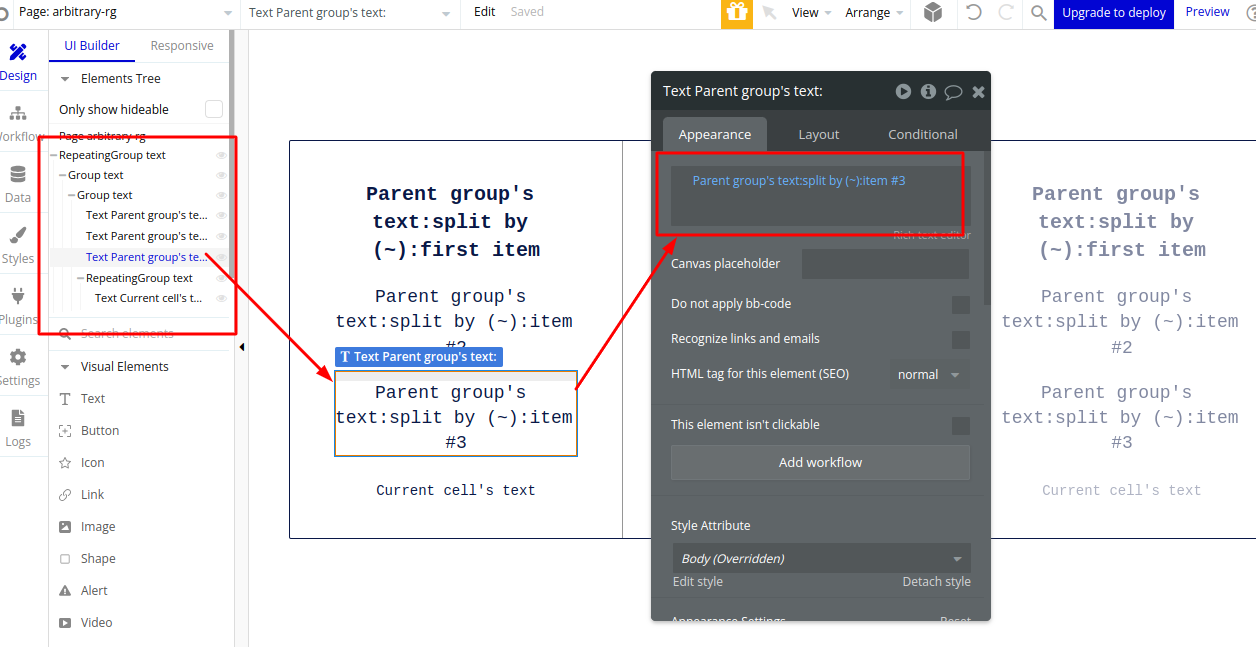
For the Product name, I am using the Text field in which text is ‘Parent Groups’ text: split by(~)first item’ which will make Product 1, Product 2 and Product 3 as a Text of all three cells of Repeating Group.
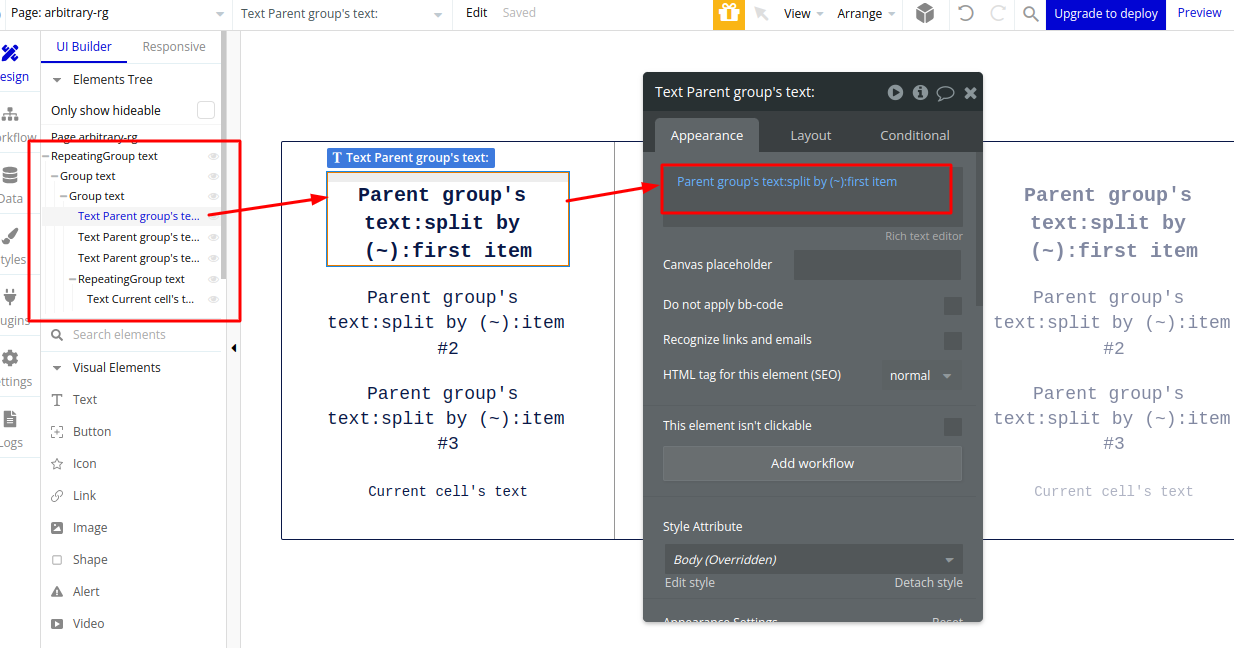
For Product Highlight 1 and Product Highlight 2, I am using the Text fields in which text is ‘Parent Groups’ text: split by()item#2’ and ‘Parent Groups’ text: split by()item#3’ which will make Highlight 1 and Highlight 2 as a Text of all the cells for each product of Repeating Group.
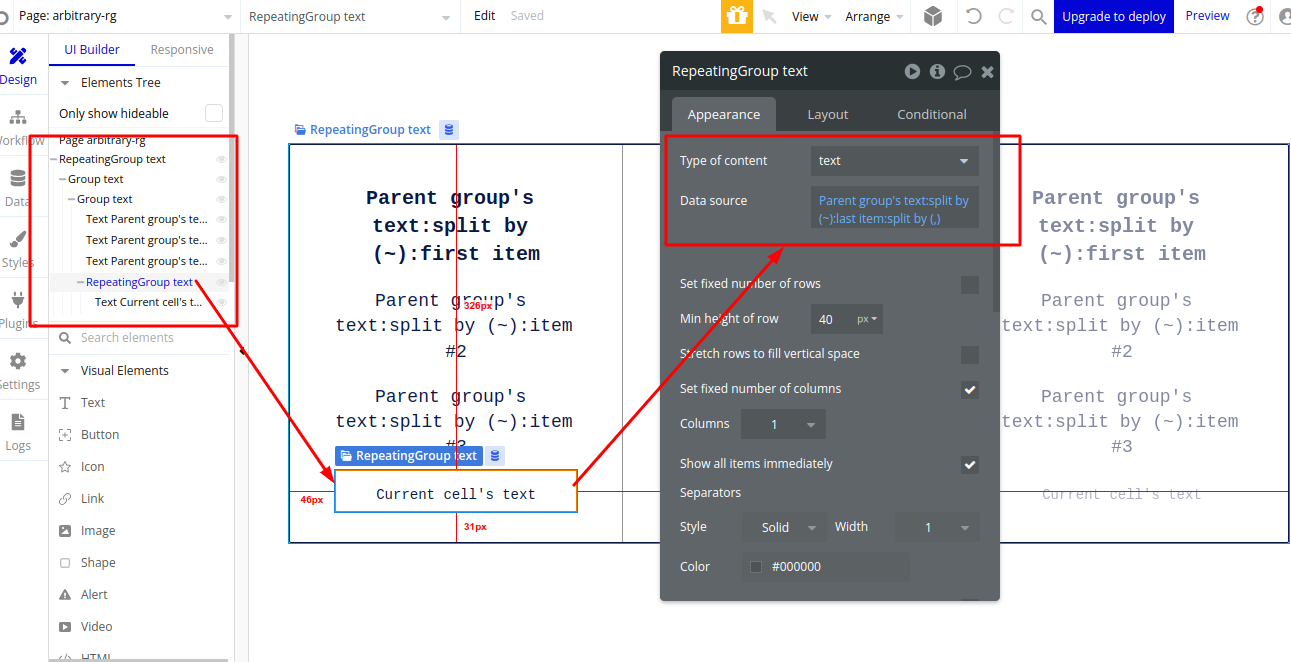
Now to show Product Features in this product details Repeating Group, I am adding another Repeating Group which will make this a ‘nested Repeating Group’ (Repeating Group in Repeating Group). Why I am doing this? Because a number of features are changing based on the product. In our example, Product 1 has 4 features. Product 2 has 7 features and Product 3 has 10 features. With the use of a Repeating Group for features, the Number of Rows that will be created in this RG of Bubble will be equal to the number of features.
The data source of this second repeating group is ‘Parent Group’s text:split by(~)last item:split by(,)
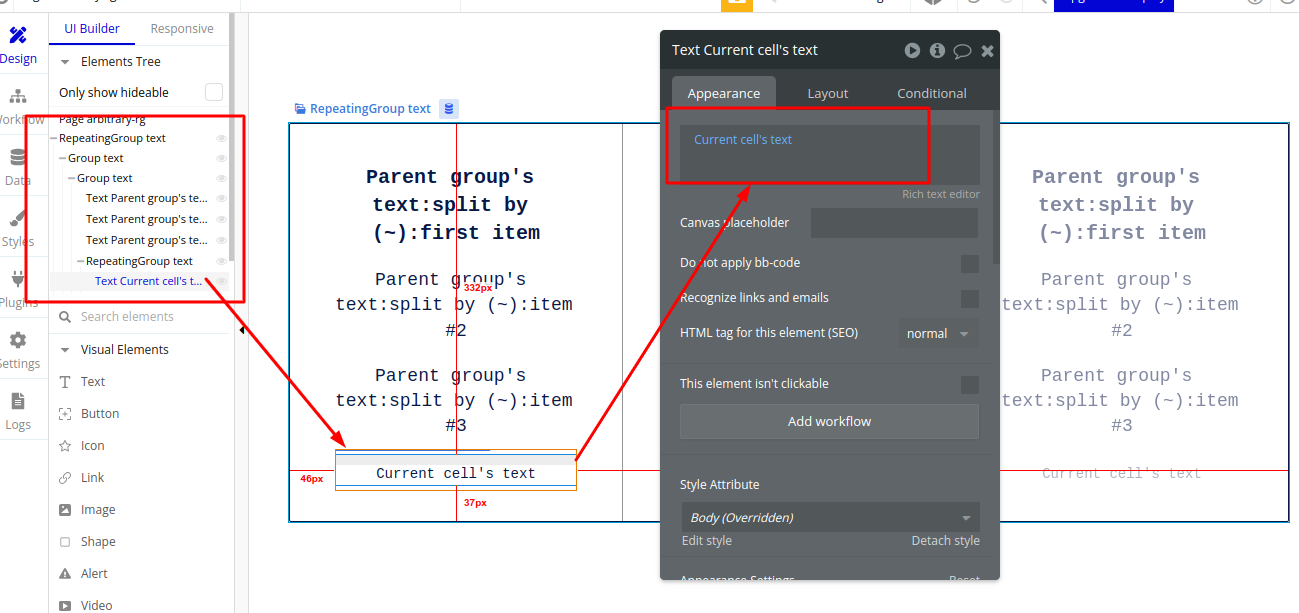
After this, Just simply going to put text in the Repeating Group as ‘current cell’s text)’
The end result of the main repeating group will look like this:

Now You can style this repeating group however you want as per your figma or design or your imagination. But here is the biggest advantage of this nested Repeating Group.
-
This Repeating Group will not fetch product/package/service/static-list-of-data details from the database.
-
The data source of the Repeating group is being stored in the Repeating Group itself using ‘Arbitrary Text’.
Yes, Many of you might think this is a headache, worthless or not the best way and I would say I agree with you but I am not limiting myself to traditional conservative practices. I am all game for trying new things to optimise all applications I am creating on Bubble. This is me doing so and sharing here because Yes, I have achieved little and consistent performance and WU optimization using this technique for a static list of data.
To discuss more, connect with me on LinkedIn.